MAD Bugs: QEMU and UTM Escape
In which the guest VNCs into its own host and watches the heap like a screensaver.
This post is part of MAD Bugs, our Month of AI-Discovered Bugs, where we pair frontier models with human expertise and publish whatever falls out.
Before we dive in, one piece of news. Dion Blazakis and Stefan Esser are joining Calif. Dion just
escapedleft the fruit company, so we thought it'd be fitting to drop a macOS VM escape exploit.
Our targets are QEMU and UTM. QEMU is the open-source machine emulator and virtualizer that powers most Linux virtualization stacks: libvirt, OpenStack, KubeVirt, and the KVM side of many cloud platforms. UTM is the App-Store-friendly macOS and iOS frontend that wraps QEMU. It ships to roughly 30K GitHub stars worth of Mac users who want to run Windows or Linux on Apple Silicon without dealing with VMware (which is technically free now but rumor has it requires a blood donation to the suckers at Broadcom before the download link appears).
We noticed UTM bundles its own QEMU (10.0.2), and that there is a version drift between what UTM ships and upstream. Our first prompts to Claude were:
find any vulnerabilities patched between the UTM version and latest which could be used as an escape on UTM?
audit qemu for a new guest-host escape which specifically would work on mac/osx/utm.
With a handful of further prompts, it found a guest-to-host code execution chain in QEMU's virtio-gpu device, and wrote ~1,500 lines of C that compile to a single static binary. Drop it into an unprivileged process inside a vulnerable VM and Calculator opens on the host.
Note on impact: There’s been some discussion about the impact of this exploit, so we want to clarify what we’re claiming. The VM security model assumes you have root in the guest and that the guest runs untrusted code. This exploit breaks that model in QEMU: we escape from the guest to the host and run arbitrary code there.
The chain does require QEMU’s VNC server to be enabled. VNC is the default in most headless deployments (Proxmox, libvirt, OpenStack), though UTM ships with it off. On UTM, the VM also has to have been configured in emulation mode, since UTM defaults to virtualization via Apple’s Virtualization framework, which bypasses QEMU entirely. The threat model isn’t “trick a user into downloading a preconfigured malicious UTM image.” It’s “an attacker who already has root on an isolated VM that’s running on UTM in emulation mode with VNC enabled.”
On macOS, apps also run inside Apple’s App Sandbox, so a full escape would need a second bug. We don’t think that layer is particularly strong, but we now need another bug to prove ourselves right.
Modern memory-corruption exploitation needs two primitives: a write to corrupt state and a read to defeat ASLR and learn where to aim it. This bug hands over the write for free; the read is the novel part, and as far as we can tell a public first: a memory disclosure through QEMU’s own VNC server, reached over SLIRP loopback from the guest itself.
Concretely, the guest opens a TCP socket to its own host’s VNC port through QEMU’s emulated NIC at 10.0.2.2:5900, sends a FramebufferUpdateRequest, and QEMU happily serializes a region of its own heap as pixel bytes back to the guest, which is now watching QEMU’s address space as if it were a screensaver. Claude assembled that read primitive autonomously from a single prompt:
figure it out the best way possible. do not modify qemu source. it needs to work from guest only. investigate turning the write to a read.
None of the published QEMU escapes we reviewed (OtterSec's virtio-snd, Talbi/Fariello's RTL8139, the older SLIRP ICMP leak) use the VNC server as an info-leak vehicle.
It turns out that the vulnerability was reported via ZDI (ZDI-CAN-27578) and fixed in QEMU 11.0.0 (April 21, 2026), but not backported to any 10.x stable. We didn't know that going in, and the rediscovery is a story in itself.
Even though this escape is now patched, it probably lasted longer than Cloudburst.
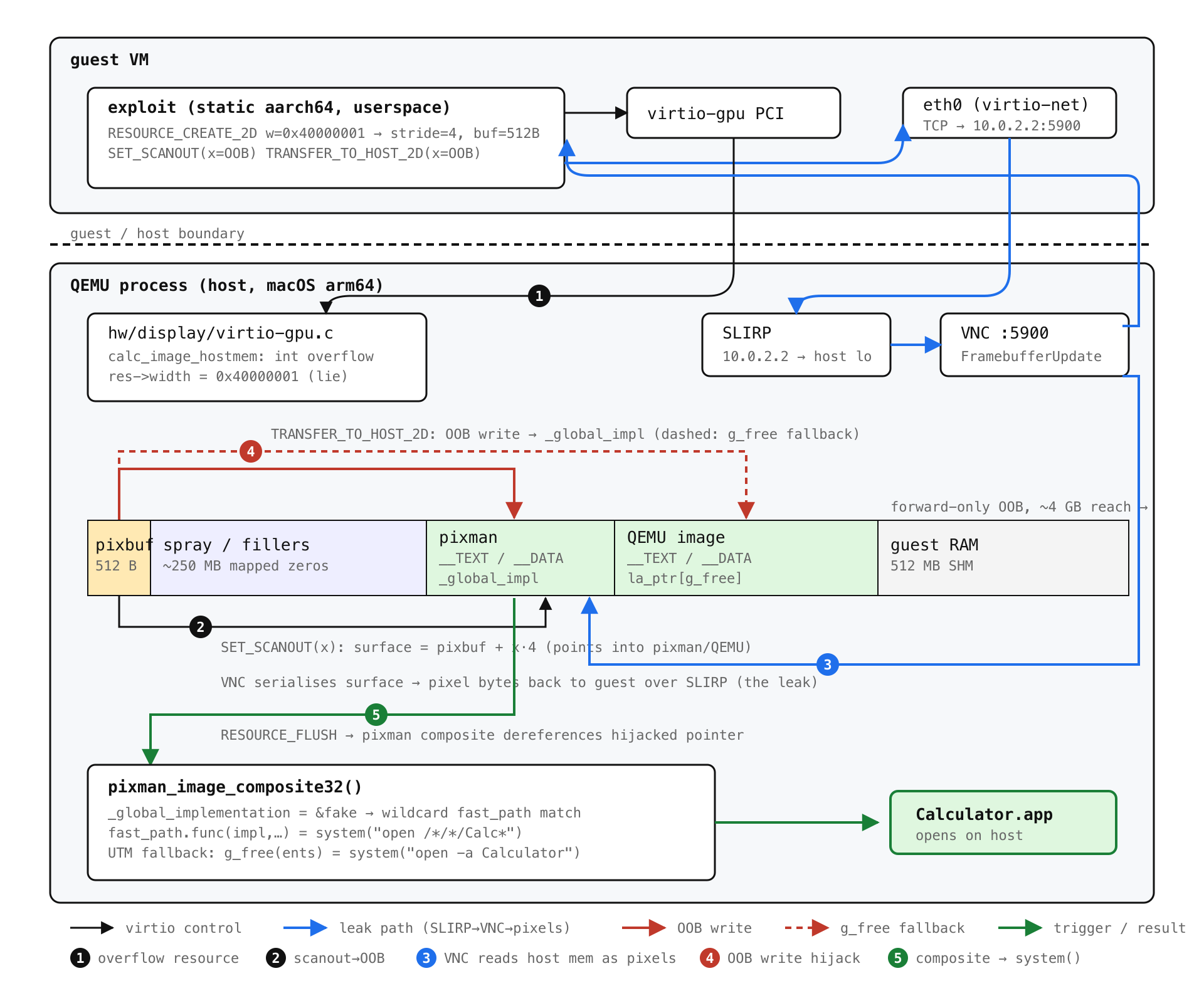
The bug
hw/display/virtio-gpu.c has a function, calc_image_hostmem, that computes how many bytes to allocate for a 2D pixel buffer:
static uint32_t calc_image_hostmem(pixman_format_code_t pformat,
uint32_t width, uint32_t height) {
int bpp = PIXMAN_FORMAT_BPP(pformat);
int stride = ((width * bpp + 0x1f) >> 5) * sizeof(uint32_t);
return height * stride;
}A quick aside on pixman, which will keep showing up: it is the low-level 2D pixel-manipulation library that backs Cairo and the X server, and that QEMU uses to represent every display surface in the system. A pixman_image_t is essentially a (format, width, height, stride, raw pointer) tuple plus the compositing/scaling routines that operate on it. When QEMU's virtio-gpu allocates a 2D resource for the guest, it is allocating a buffer and wrapping it in a pixman_image_t.
Every intermediate in calc_image_hostmem is a 32-bit int. For bpp = 32 and a guest-supplied width = 0x40000001, the width * bpp multiplication wraps, the round-up-to-32-bits trick rounds the wrong number, and stride collapses to 4. With height = 128, calc_image_hostmem returns 512. QEMU then allocates 512 bytes, hands them to pixman as pixman_image_create_bits(BGRA, 0x40000001, 128, ptr, stride=4), and stores the original, un-overflowed 0x40000001 in res->width.
Every later bounds check on this resource (in set_scanout, in transfer_to_host_2d) checks against res->width. Which is a lie. The guest can address pixel coordinates up to ~4 GB past the actual 512-byte buffer.
That is the entire bug, but the why of it is interesting. Pixman's pixman_image_create_bits(format, width, height, bits, rowstride) has two modes. Pass bits = NULL and pixman allocates the buffer itself, performs its own overflow check, and ignores your rowstride. Pass bits = <pre-allocated pointer> and pixman trusts you completely: it uses your pointer, uses your stride, and runs no checks, because by API contract the caller has already validated.
Before a 2023 commit, virtio-gpu used the first mode. calc_image_hostmem existed, but only to compute res->hostmem, the per-VM accounting number used to enforce memory budgets. Pixman did the actual allocation, and pixman caught overflow. The buggy int stride was lying about a counter, not a buffer size.
The 2023 commit switched to the second mode. Windows display surfaces need a shareable HANDLE, which means the buffer has to be allocated by QEMU with qemu_win32_map_alloc(), not by pixman. So virtio-gpu started allocating calc_image_hostmem(...) bytes itself and passing the pointer and stride into pixman. The commit message even flags the behavior change:
when bits are provided to pixman_image_create_bits(), you must also give the rowstride (the argument is ignored when bits is NULL).
Pixman dropped its overflow check because the API contract said it could, the same buggy function went from accounting counter to trusted allocation size, and nobody re-audited it. The caller did not validate.
The chain
The bug gives an OOB write directly: transfer_to_host_2d will happily copy guest-controlled bytes to pixbuf + x * bpp for any x < 0x40000001. What it does not give you, on its own, is an OOB read, which means no ASLR bypass, which means the write is mostly useful for the host process.
The way Claude solved the read-primitive problem is, we think, the prettiest part of this exploit, and we want to walk through it because it took us a minute to believe.
set_scanout is the virtio-gpu command that says "this pixman_image_t is the active display surface; show this on the screen." The bounds check on its arguments uses the same broken res->width, so the guest can configure the active display surface to point at memory 1 GB past the 512-byte buffer.
QEMU has a built-in VNC server. Its job, by definition, is to encode the active display surface as pixel data and ship those bytes to any TCP client that connects to port 5900.
QEMU's default user-mode networking stack, SLIRP, makes the host reachable from the guest at 10.0.2.2. So the guest opens a TCP socket to 10.0.2.2:5900 (its own host's VNC port, reached through QEMU's own emulated NIC), sends a FramebufferUpdateRequest, and QEMU's VNC server politely serialises a region of its own heap as pixel bytes back over the socket.
A FramebufferUpdateRequest returns width × height × 4 bytes, so reads are 16 KB pages at scan time and 256 bytes for targeted lookups. Encoding host memory as pixels has the lovely side effect that there is no protocol-level interpretation, no parser, no escaping; every byte of the address range comes back unmangled, just slightly fewer per second than you'd like.
From the read primitive it's a fairly textbook macOS arm64 chain. Scan forward 16 KB at a time looking for Mach-O headers; identify pixman by sizeofcmds; read GOT[free] to derive the shared cache slide; compute system(). Plant a fake pixman_implementation_t whose fast_paths array has a wildcard entry whose func is system(). The implementation pointer is the first argument to func on arm64, so we put the command string at offset 0 of the same struct and let it serve double duty. Two more OOB writes neutralise pixman's TLS fast-path cache and overwrite _global_implementation. A final RESOURCE_FLUSH triggers a VNC composite, pixman walks our fake chain, the wildcard matches, system() runs.
The command string has to fit in 15 bytes (the fast_paths pointer lives at offset 0x10), so open -a Calculator is too long. open /*/*/Calc* is exactly 15, and /bin/sh expands the glob to /System/Applications/Calculator.app. (Our first attempt, /S*/A*/Ca*, also matched Calendar.app, which made for a less convincing demo.)
UTM adds one more twist. Its QEMU allocates virtio-gpu pixel buffers through qemu_pixman_image_new_shareable, which is memfd + mmap rather than malloc, so the exploit buffer lands in an address-space hole between UTM's twenty-odd bundled frameworks instead of out in the large-object heap. dyld shuffles those frameworks on every launch, and on a meaningful fraction of boots pixman (2.4 MB, one of the smallest) ends up at a lower address than the first hole big enough for our buffer. The OOB write only reaches forward, so pixman's _global_implementation is then physically behind us and the hijack above cannot land.
The fallback is to target QEMU itself. Its image is a 29 MB block, large enough that the buffer essentially never lands above it, so the scan carries a second fingerprint table for QEMU's __TEXT and derives system() from QEMU's GOT instead. The control-flow hijack moves to QEMU's __la_symbol_ptr[g_free] (writable, ~70 MB forward, comfortably in range): one OOB write points it at system(), and the trigger is a deliberately short RESOURCE_ATTACH_BACKING whose entry bytes spell the shell command. virtio_gpu_create_mapping_iov g_mallocs a scratch buffer, copies our bytes in verbatim, fails the length check, and on the error path calls g_free(ents), which is now system("open -a Calculator"). A nice side effect is that this path has no 15-byte limit; the command can be as long as a virtqueue descriptor.
The chain needs the guest to reach a VNC server. That is the default almost everywhere headless QEMU runs: Proxmox, libvirt's stock <graphics type='vnc'/>, OpenStack, every CI runner that boots VMs with -vnc :0. On UTM it is non-default, and requires a one line config -vnc :0. The bug itself is present in every UTM install regardless.
Reproduce
The PoCs and AI-generated write-up can be found here:
./run_poc_macos.sh # ~5 min: install deps, build QEMU 10.0.2, build exploit
./run_poc_macos.sh run # ~30 sec from boot to calcConclusion
One thing we do not know is how Claude arrived at the bug. Our first prompt asked it to diff UTM's QEMU against upstream, and the fix commit was already public; it is possible the model spotted c035d5ea and worked backward, and equally possible it audited virtio-gpu.c cold and rediscovered the overflow on its own. We cannot tell from the transcript, and either answer is kinda cool: one means a frontier model can mine patch diffs into working escapes faster than downstreams can ship the patch, the other means it can find the same bug ZDI paid for without being pointed at it.
While the bug is a simple integer overflow, the exploit is, as far as we know, the first documented case of AI doing creative exploit primitive design: wiring three unrelated QEMU subsystems (virtio-gpu, the VNC server, SLIRP loopback) into a leak nobody had published before.
From there it ported the chain to Linux aarch64, rebuilt it as a SPICE-safe UTM variant after we reported the original crashed under UTM's display-refresh thread, pivoted from "overwrite GOT[free]" to writable BSS when macOS chained-fixups turned out to make the GOT read-only, and added the QEMU-g_free fallback when ASLR put pixman behind the buffer. None of those pivots involved a human pointing at the answer; the full prompt log is a dozen one-liners.
However, Claude hasn't (re)discovered fancy tricks such as KMART or MHST[^1] for this exploit, so the super humans among us still have some edge over it. At least for now.
[^1]: Kortchinsky-Midturi ARM ROP Technique and Midturi Heap Spray Technique. These are legendary exploitation techniques invented by the MSRC and SWI Pentest team fifteen or so years ago. CC @crypt0ad